研究テーマ
研究テーマは学生と教員の話し合いにより決定します。
以下に研究テーマの例を挙げます。
(最近の研究テーマについては、研究発表のページ
をご覧下さい)
■自然言語の意味解析

言語の意味を理解するというのは、言語表現をそれが表している実世界の事物と関連付けることであると言うことができます。 そのようなことを行うには言語に関する知識と言語以外の知識の両方が必要となります。 言語に関する知識としては辞書、文法、意味の体系などがあり、 いずれも大規模なデータとなるため既存の電子化辞書を活用することが有効と思われますが、 多様な知識を単に寄せ集めるのではなく適当な言語モデルに基づいて整合的に利用することが望ましいと考えています。 一方、言語以外の知識には常識(例えば、時間、場所、社会に関する知識)と 当該分野の専門知識(コンピュータに関する文章ならばコンピュータの知識)が必要になります。 これらに関しては、人工知能の分野で検討されている知識表現の手法を参考にして一貫性と再利用性の高い形式で記述することが重要です。 本研究では、これらの知識の構築とともに自然言語の意味解析の自動化の研究を行います。
この研究テーマは、本研究室で行われるあらゆる研究の基盤となる研究です。
■自然言語インタフェース
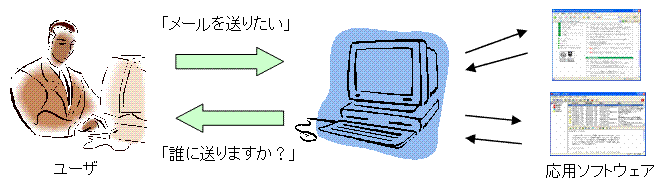
情報技術の発展・普及により多くの人が日常的に情報システムに触れるようになりましたが、 そのようなシステムの多くはいまだに操作が難しく専門知識が無いと不自由な思いをすることが多いのが実情です。 そこで私たちは日常的な言葉を使って誰でも気軽に情報システムにアクセスできるようなユーザ・インタフェースの開発を行っています。 ユーザが自然言語を使って指示を入力すると、システムはその意味を理解し、処理を実行したり、ユーザに対して再び自然言語の形で情報を提示します。 分からなかった点を聞き返すなど人間と機械が対話的にやり取りを進める対話型インタフェースの研究も行います。
研究テーマの例:
- ヘルプ文書を利用したソフトウェア操作に関する質問応答システム
- Webから抽出した知識を利用するパーソナル情報検索エージェント
- 日常言語によるプログラミング
■Web上の言語情報処理
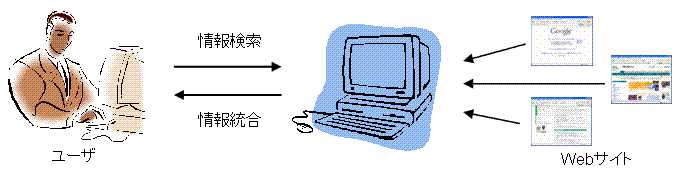
World Wide Web上で提供される情報、知識、サービスの種類と量は近年爆発的な勢いで増加しています。 この急激な変化に対応して、ユーザが必要とする情報を素早く的確に検索できるようにする技術や、 Web上のあちこちに分散した情報を統合して見やすく提示する技術が求められています。 このような技術を実現するためにWeb上の情報にメタデータを付加するSemantic Web等のアイデアが提案されてますが、 私たちはさらに自然言語テキストの意味解析技術を応用することによって、 Web上にある情報や知識を最大限に活用してユーザの知的な活動を支援することを目指しています。
研究テーマの例:
- Web上にある事実的情報および評判情報に基づく映画推薦システム
- Web上の料理レシピ情報の検索
- Folksonomyにおけるタグの相互関係の分析